I’m continuing the series of articles about developing a Geo Information System for 2GIS company.
In the first article I described the requirements we gathered. Now it’s time to talk about the implementation.
We decided to go with 3-tier architecture. We stored the data in the Microsoft Sql Server database. Spatial columns, which worked really well, held the geometry. It was the master database, one instance for everyone, and all writes went there. And reading was performed from different types of “slaves”, and I’ll talk more about it in the next sections, as it’s a very interesting topic.
The server side contained logic to retrieve the data and to save it; and to perform validations on it.
The client displayed the map with all our geo objects, and it had many special instruments for our cartographers to work with the geo data and its attributes. Naturally, it talked to the server in order to get the data or to save it.
By the way, we called the new system Fiji. Here’s why.
Problem with data reading
While working, a cartographer moves around the map like crazy! They zoom out and pan, and zoom in, and pan, and pan again. We calculated that on average, a cartographer sees on a screen up to several megabytes of geo data. And they move every second, loading new data.
We had one master database with all data. And we had lots of users, who wanted to query that data.
But how do cartographers query the data? Not with raw SQL queries, for sure?
As it turns out, a geo object can be represented in many different ways. Users want to see it on the map, with all fellow geo objects around. Users can search for it by attributes. They want to see its attributes and edit them. They wish to see the history with its changes. They need check if it’s correct, according to their technology.
When a cartographer performs all these operations, they actually query the geo data.
Now, we can query it directly from the database. But if we have many users, and they all perform many operations, then the database speed is just not enough.
Don’t forget about network latency. If you are in Chile, and the database is in datacenter in Moscow, the ping times can reach 300+ ms. Or if you’re in a small Russian town with bad internet providers, then sometimes it’s even more. Sad, but true.
If every move on the map is performed with 300-millisecond lag, it’s almost not possible to work. Imagine that you get 300-millisecond delay every time you scroll this page?
So you want to do both things at once: “free” the database from the load, and also eliminate the network delay on the most critical operations.
Dedicated server for map display: tile server
We needed scalability, so we went with creating dedicated caching servers for specific read types.
First we decided that the first most important operation is the map display. It’s what our users do several times per second. So we created a dedicated server for this specific operation. It deserves a separate article about it, as it was so interesting to think about it and to develop it, really!
UPD: there’s now a separate article about it.
So, we developed a special server, optimized for the purpose of map display. It held data in a very specific, very optimized format, so we could very quickly get geo objects to display on users’ screens. It served only one purpose, but it did its job very well. We called it a “tile server“.
We installed a tile server in every office around the world, so we ended up with more than 100 instances. Because cartographers from a given city work mostly with the map of this city, we assigned the “main area” to each instance.
When a new server was set up, we ran a special job, which read the data from the master database and cached it in this optimized format. It queried all the data in the “main area” it belonged to. When the job has finished, the tile server was ready to serve users in its city.
Additionally, a special job queried the master database every several seconds, and if it found any new data updates, it also added them to the cache.
Perfectly horizontally scalable!
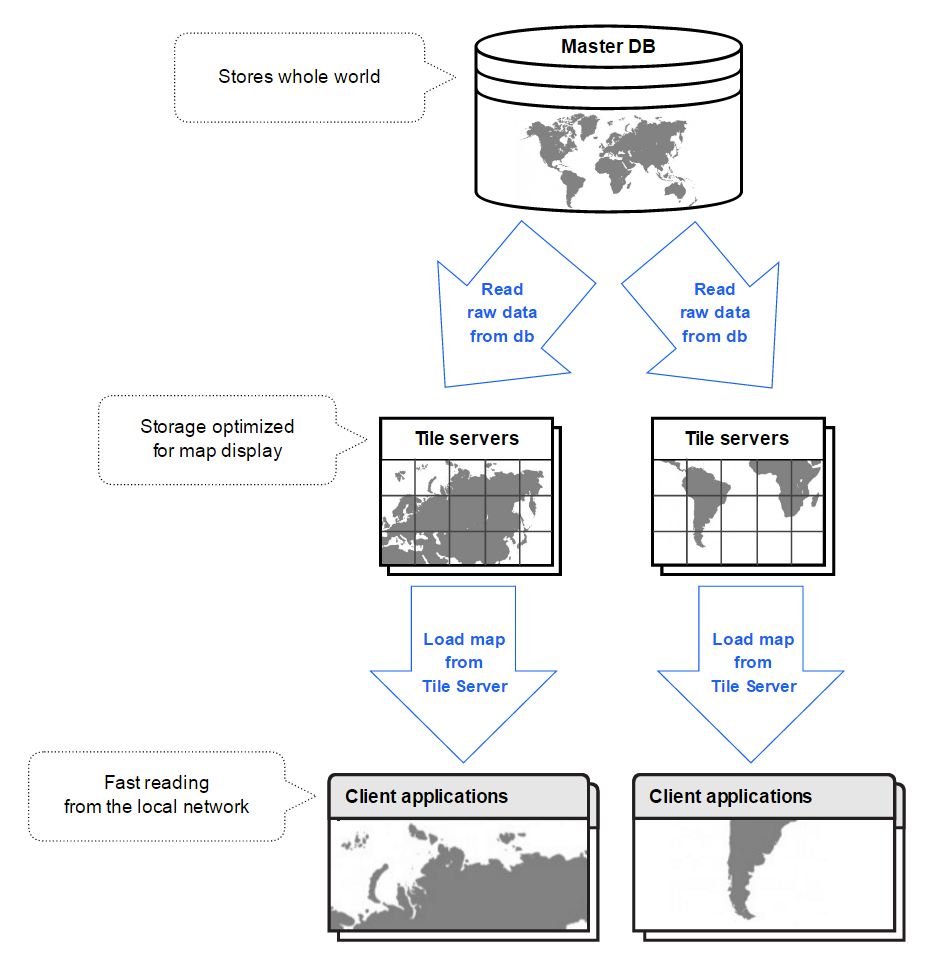
Since such a server was located in the internal network of the office, users didn’t experience network delays when moving around the map anymore. And since the data format was really optimized, we could serve the map very fast to all our users around the globe.
Search server
We really liked how it went with tile servers. The map loading times were small, and users were happy.
Next we had to implement the search feature.
Users wanted to search for geo objects by their attributes. For example, they wanted to find all buildings in their city with >5 floors, with areas <50 square meters, created between March and May last year. And they must intersect this weird geometry they just drew.
They didn’t perform this operation as often as map display, but it was pretty important for them. They didn’t want to wait ages for their search results.
So we installed ElasticSearch and put our data in there.
ElasticSearch has its own spatial index, but it isn’t a “precise” one. If you search for all geo objects strictly inside a geometry, you’ll get a small number of false positive results: ElasticSearch will say they are inside, when they are not. We wrote a small plugin to filter the results and remove these false positives.
With simpler attributes, like strings and numbers, we didn’t have any problems.
We wrote a job to fill a new instance of ElasticSearch with the data, and a job to periodically refresh the data, if there’re updates.
We installed several instances of Elastic all over the world, but not in every office, like we did with tile servers. Still, it was acceptable, the ping times didn’t hurt that much, as the users were willing to wait a tiny bit more.
Validation server
Users wanted not only to query the data, but also to check if it’s valid. They wanted us to create lots of validations, from simple ones (all city geometries do not intersect each other) to more complex ones (if the graph of all roads in the city is valid).
We created a separate server for running those validations.
It cached only previous results, but not the data itself – it always queried the master database to get the freshest data.
But it was a separate server on a separate machine, because validations could be really long and memory- and processor time-consuming.
We set up only one validation server initially, because it was enough for now. Nevertheless, it is also scalable in the same way as tile servers. You just install the new instance on a separate server, where and when you need it, and that’s it.
Graph server
We had a road graph. It consisted of all roads, which were represented as linear geometries. Ends of these linear geometries were connected, i.e., placed at one point. This connection meant that you can drive a car or walk from one linear geometry to another.
On these points users could also define limitations or, as we called it, “forbidden maneuvers”.
Sometimes cartographers make mistakes. They can accidentally forbid wrong maneuvers on a crossroad. Or the can set schedules incorrectly, so a certain road becomes permanently closed. Maybe they set the road direction incorrectly. Or they don’t connect two road lines properly, so there’s some space between the road ends. All these mistakes mean that you can’t drive a car there, or you can’t walk through, or the bus goes a very different way than in reality.
Our users wanted to find mistakes like that automatically.
A graph of one city could be as big as several hundreds of thousands of geometries.
So we also used a third-party solution – Neo4J. It’s a graph database, which means that it’s very useful for storing graphs… obviously :).
It could build routes, so our users could check small parts of the road manually. If the routing algorithm goes like you expect, then it’s okay. If it doesn’t go through this particular point, there’s a problem.
Now, for validation of bigger graph pieces we implemented Kosaraju’s algorithm as a plugin. That algorithm checks the given graph and returns the number of strongly connected components within the graph. If it’s one component, it means that you can get from any point of the graph to any other point, and it’s great. If there’re more components, it means you’ll get stuck. If your home is in one component, and your work is in another, you’d better call your boss and say you’re not coming because your map told you so. All this graph validation also deserves a separate article, for sure.
Just like with previous servers, we wrote a job to fill the graph database initially, and a job to update the changed geometries.
Just like with validation server, we set up only one instance of a graph server, but it’s also scalable in the same way.
Read here about specific road graph validations we have implemented.
“Map server”
Finally, sometimes you need to read the data, modify it, and write it back to the database. Nothing fancy.
This is a task for the main database.
With “write” operation everything is clear. You have a master database, you write to it, that’s what master is for. (Then fancy slave servers will read your update and modify their specialized storages accordingly.)
But why didn’t we move the “read” operation to its own separate server closer to the user, and save the time? Like we did with tile server?
Well, servers like this have a certain delay before they catch up with all the changes. Maybe it’s several seconds, but in this case it was very important.
You see, our cartographers update geo objects pretty often. When they click on a geo object to edit it, we really wanted them to get the freshest version of this geo object. Otherwise, they would often see the previous version of the object, updated by a colleague just a couple of seconds ago. They would modify it and try to save it, and they wouldn’t be able to do so, because the didn’t edit the last version. This is not good.
So we had a single instance of map server, which performed all read and write operations, and also ran some small validations. This one is not scalable, because the master database exists only in one instance too.
Yes, in this case we had these ping delays, but, well, what do you do.
UPD: an article about Map Navigation is now ready!
3 thoughts on “Geo Information System: Architecture”
Comments are closed.