If you ask me, what’s a single most important thing in writing good code, I’d reply: “Modularization and Dependency Management”.
Well, actually, that’s two things. Sorry about that! But they are two sides of the same coin, and you can’t have one without the other, if you want to your code to be nice and clean.
Long story short: modularize the code and let every part of it serve only one specific purpose.
That’s one most important quality of the code: proper modularization and proper dependencies between modules, or blocks.
The ultimate recipe for good code
That’s one loud header, but the steps are actually pretty simple and even might look obvious, when you think of it.
🙂
Any module of the application, however big or small, should follow these three simple rules:
- It should have one specific responsibility.
- If other blocks are going to use it, they must use its API. They must not have access or any knowledge of this block’s internals.
- If it uses other blocks, it should use their APIs. It must not use any of their internals.
What are dependencies and APIs?
An API is an interface or a protocol of a given service which lets you use this service.
And implementation details of that service would be everything inside it that lets it do its work. Cogs and wheels.
For example, if we were talking about a big web application, a service A could call the REST API of a service B. In this case the API of the service B would be, well, the REST API – all these nice POST, PUT, GET and DELETE methods which service B provides, as described in its documentation. (You do have documentation, right?)
Of course, it can be SOAP API too. The point is to have a bunch of defined endpoints which you can call and this way ask the service to do stuff.
In any case, we could say that service A depends on, or has a dependence on service B. Probably it’s called a “dependency” because A can’t do its work without B’s help.
If we are talking about classes, it would mean class A calling another class B’s method. Then the API of that class B would be – its public methods. The internals of class B are its protected and private methods, and class A and the developer of class A are not supposed to know anything about them.
If it was about functions, it would be one function A calling another function B. The function’s API is its definition: name, arguments, and return type. The internals of the function is its specific implementation.
In general, if one of your modules needs help from another one to do its work, it’s a dependency.
Diagrams with rectangles and arrows
Let’s have a look at the following picture. The modules here have very clear dependencies, and a small number of them, so the whole picture is very easy to understand. Also note that one module depends on other module’s API, not on its implementation details.

And, though it’s not reflected on this abstract picture, every module has its own piece of work to do. It doesn’t do two or three things at once. No multitasking.
We need to go deeper!
You’ll notice you can go deeper recursively, where each bigger block has smaller parts, which have their own small, but clearly defined responsibilities.
Let’s zoom in into Module 2 from the previous picture. It consists of smaller modules, and I called them submodules. The Submodules also have dependencies on each other and on other bigger modules outside of Module 2.
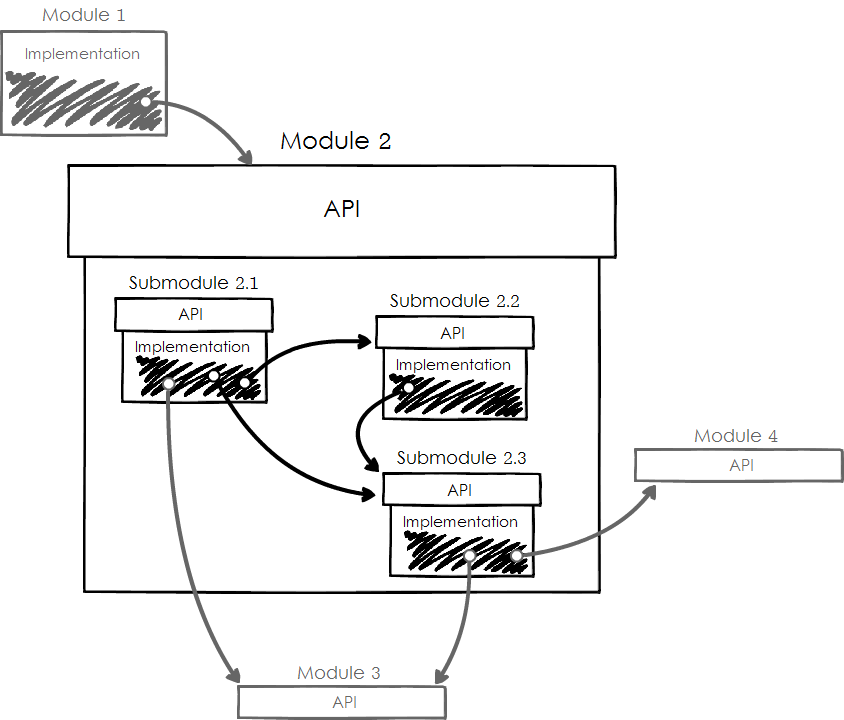
But they still follow our Three Principles: they use each other APIs, they don’t flash out their internals, and they modestly don’t peek into other modules’ internals.
Of course, you can go even deeper and draw a diagram of any submodule. If done properly, it would be the same in essence.
These principles are important on any level.
How does it help?
Firstly, the code that follows our three rules is easy to understand. These rules make the code readable, you can follow it through and understand what it does. You can go deeper into details or step back and look at the bigger picture. On any level, you’ll find the same neat structure.
You can explain it to someone else. You can even easily draw a picture like the ones shown here, and show it to your colleagues.
Secondly, if it’s easy to understand, it’s easy to change when needed.
Thirdly, you can localize your change so that you’ll edit only parts that need the change. If you have your APIs in place, you can just change the implementation, and all dependent modules will stay blissfully ignorant.
Big Talks about Architecture
You can easily explain it to your colleague on any level of details. If you’re talking to your manager or speaking in a conference, you’ll draw a diagram with biggest blocks, for example, database(s), server application(s), and client application(s). Everyone will understand your system quickly and, of course, will stand in awe before your genius! 🙂
Ever noticed how pictures in articles and talks about Big Systems Architecture have the very similar presentation: usually, blocks and arrows, like here, in this article?
Noticed how arrows always go in one general direction?
It’s because this principle is applicable to any level of abstraction in software development.
Small talks about smaller things
If a fellow developer explains to you the details of the feature they just implemented, they will probably talk about small blocks. It could be a couple of classes with five functions or so. The classes and the functions would depend on each other, just like Databases and Servers. And if you try to draw a diagram of them to understand them better, it’ll still look the same.
Refactoring
Now, what happens if you want to rewrite a piece of code? Let’s you’d like to improve the Submodule 2.3 from that picture. But Submodules 2.1 and 2.2 depend on it! Is it wise to touch it? Won’t the others break?
The best thing is – no one outside of Submodule 2.3 cares what’s inside it! All modules which use it know only about the API. This means you can change its insides however you want.
Exactly the same thing goes about bigger modules. Module 1 depends on Module 2‘s API. It doesn’t know a single thing about Module 2‘s internals. It doesn’t care about any Submodules and their dependencies but its own.
Now, what happens if you find the whole Module 2 ineffective and want to rewrite it? You guessed it! You just change Module 2‘s internals in any way you like, but all other Modules won’t notice. You can pull it off because you modularized the code properly and managed dependencies properly. Congratulations!
And again, this goes on all levels.
Example of a small refactoring
Say, you have a method that loads user names from the database, sorts them, and returns them to display somewhere in the user interface.
It’s quite possible your small diagram with modules and dependencies would look like this.

Noticed we’re using bubble sort in here? When you have five user names, it’s all fine. When you have more, it becomes a problem.
So, you might want to rewrite your swap() function to make it more effective. Then all your other code stays totally the same! You just change the internals of the swap() function, and the sort() method still works. And the getUserNames() works too. And the code that displays the results of getUserNames().
Or, maybe you want to change the bubblesort to something else, a bit more effective. Then you’ll change the implementation of the sort() function, but getUserNames() won’t notice.
See? You make changes only in necessary code parts, but all other parts that depend on it can stay the same. Neat!
Example of a big scale refactoring
On a bigger scale, managing separate blocks is even more important, than on a smaller scale!
Let’s imagine you have an application with some two server-side applications, one client, and a database. The architectural diagram might look like this:
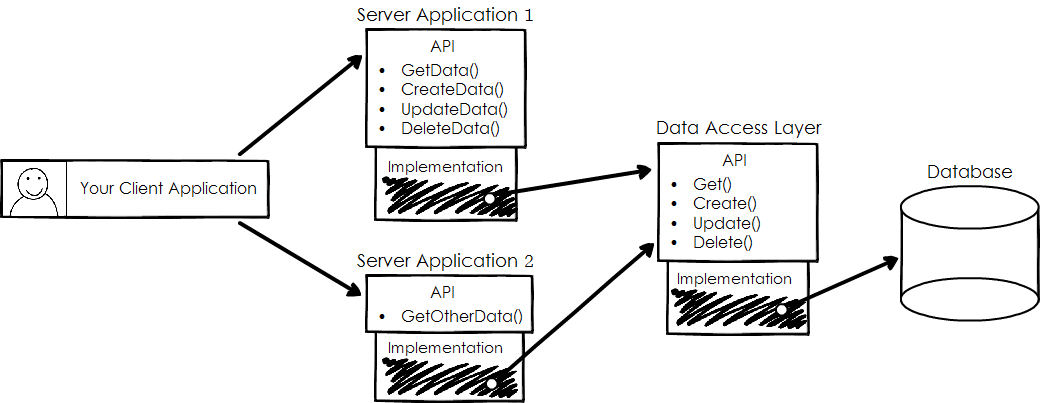
Now, let’s say it’s been working for some time, and everything was good, but now the business grows, and you want to optimize the Server Application. If you want to rewrite the Server, you just need to keep its APIs intact. Then all other parts will stay the same, because you took good care about keeping the APIs.
By keeping the APIs the same, you have several advantages:
- You don’t have to change the client code. You have isolated part of your work, and you don’t need to do more. That’s nice, isn’t it?
- You don’t have to provide everyone with the updated Client application. It’s not always possible. Imagine that your application is a desktop or a smartphone app. Not everyone updates an app the very instant the developers released a new version!
Why it’s very-very important on a bigger scale
Why else are modularization and managing dependencies very important on a bigger scale? Because it’s harder to fix mistakes.
If you made a mistake and tied the dependency knot tighter than needed between your two private functions in a class, that’s not a big problem. You can untie it in ten minutes. Easy.
If there’re two classes tied together so that there’s a circular dependency, you’ll probably have to spend a couple of hours trying to understand what’s happening and how to untie them. Perhaps, you’ll have to introduce a third class to solve the problem, and maybe write some tests. Still, hot too hard to solve.
But if you’ve done something wrong with your architectural-scale blocks, it’s not a small thing anymore! If you forgot to split your code into server-side and client-side libraries, you’ll spend LOTS of time tidying, cleaning, and also being angry and swearing.
If it hasn’t been done in the first place, when the architecture was being developed, then it’s going to be only worse with time. New developers are not going to understand the whole picture, they are going to introduce more and more badly modularized, highly dependent code, and it’ll become a complete mess.
This state is famously called “spaghetti code”, when all modules are tied and mixed together like spaghetti on a plate.
The development of new features will slow down and will keep slowing down with time. The bugs will multiply, and fixing them will become increasingly difficult.
At one point the development process might stop altogether.
To help you avoid this entangled hell, here’s this simple recipe again:
The ultimate recipe for good code – again
Any module of the application, however big or small, should follow these three simple rules:
- It should have one specific responsibility.
- If other blocks are going to use it, they must use its API. They must not have access or any knowledge of this block’s internals.
- If it uses other blocks, it should use their APIs. It must not use any of their internals.